
티스토리 뷰
1. 데이터의 멱등성
HTTP 공부를 하면서 많이 들어봤지만 아직도 명확하게 개념이 서지 않았는데 이 기회에 정확히 알아보고자 한다.
한자로 '멱' 은 덮다, 천 같은 의미를 나타내고 '등'은 같다는 의미를 나타낸다. 일단 직관적으로 덮는데 같은? 뭐 그런 뜻이겠거니 하고 키워드를 자세히 알아봤다.
RFC에서는 HTTP 메서드의 멱등성을 이렇게 설명한다.
https://datatracker.ietf.org/doc/html/rfc7231#section-4.2.2
RFC 7231: Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content
The Hypertext Transfer Protocol (HTTP) is a stateless \%application- level protocol for distributed, collaborative, hypertext information systems. This document defines the semantics of HTTP/1.1 messages, as expressed by request methods, request header fie
datatracker.ietf.org
"
A request method is considered "idempotent" if the intended effect on
the server of multiple identical requests with that method is the
same as the effect for a single such request
여기서 request method는 get,post, put, delete, patch 등을 나타낸다.
RFC에 따르면, (제가 해석한거라 원문 보고 이해해주세요..)
어떤 메서드가 멱등성(idempotent)을 가지고 있다는 것은, 서버에 다수의 동일한 요청을 보냈을 때 하나의 요청을 보냈을 때와 같은 효과가 나타나는 것 이라고 한다.
그리고 이런 멱등성은 클라이언트가 요청을 보낼 때만 적용하는 개념이다. 클라이언트가 멱등성을 가진 채로 요청을 보낸다면, 서버 입장에서는 안심하고 각 요청에 대한 처리를 할 수 있다.
클라이언트 입장에서 어떤 요청이 멱등하다는 것은, 만약 요청에 대한 서버의 응답을 받지 못한 채로 HTTP connection이 닫혔을 때 클라이언트는 안심하고 다시 자동 요청을 보낼 수 있다. 왜냐? 어차피 똑같은 효과가 나타날 것이라 기대하기 때문이다. 즉, 서버의 어떠한 리소스나 상태에 대해서 동일한 영향을 끼칠 것이라고 예상하기 때문이다.
식으로 나타낸다면, f(f(x)) = f(x) 일 때 f(x)는 멱등하다고 말할 수 있다. 동일한 값을 여러 번 집어 넣더라도 동일한 결과가 나오기 때문이다.
그렇다면 각 HTTP 메서드의 멱등성에 대해 생각해보자.
1) GET
멱등하다. 단순 조회이기 때문이다.
단, 두 번 세 번 GET 하는 와중에 리소스가 다른 메소드로 인해 변경될 수도 있다. 멱등성은 이런 것 까지 고려하지는 않는다. 즉, 서버가 알아서 잘 처리해야 된다.
2) POST
멱등하지 않다. 예를 들어,
POST /add_comment HTTP/1.1
POST /add_comment HTTP/1.1 -> Adds a 2nd comment
POST /add_comment HTTP/1.1 -> Adds a 3rd comment이러면 여러 댓글이 추가 된다. 새로운 자원이 계속해서 생겨난다. 따라서 서버의 응답이 반환되지 않았을 때 다시 POST 요청을 보내는 것은 위험할 수 있다. 리소스가 생겼는데 다양한 이유로 응답만 반환이 안됐을 경우, 다시 POST 요청을 보내면 똑같은 리소스가 재생성 될 수도 있기 때문이다.
3) PUT
멱등하다. 근데 오... 조금 헷갈린다. PUT의 기능을 생각해보면, 기존 리소스를 덮어 씌우기 때문에 100번을 요청해도 동일한 영향을 끼치게 된다. 따라서 멱등이라고 할 수 있다.
4) DELETE
멱등하다. 백 날 DELETE 해봤자 동일한 결과가 나타난다.
5) PATCH
이 녀석이 가장 애매하다. RFC 5789에선 이렇게 표현한다.
PATCH is neither safe nor idempotent as defined by [RFC2616], Section
9.1.
A PATCH request can be issued in such a way as to be idempotent,
which also helps prevent bad outcomes from collisions between two
PATCH requests on the same resource in a similar time frame.
PATCH는 멱등할 수도, 멱등하지 않을 수도 있다.
PUT과 같이 데이터를 대체할 목적으로 요청을 하면 멱등하다. 즉,
PATCH users/1
{
name = "SOPT"
}이런 식으로 보낸다면 멱등하다. 동일한 요청을 반복하더라도 name이 SOPT임에는 변함이 없다.
멱등하지 않을 경우는,
PATCH users/1
{
$increase: 'age',
value: 1,
}사실 예시가 잘 떠오르지 않아서 구글링해서 가져왔다.. 이럴 경우 멱등성이 보장되지 않는다. 근데 request를 이렇게 보낼 경우는 그렇게 많지 않을 것 같다.
2. SpringBoot 구동 원리
2. 1
전체적인 구동 방식을 말하기 전에, 스프링부트 프로젝트 생성 시 @SpringBootApplication은 무엇을 포함하고 있는지 간단하게 알아봤다.
package com.example.testspring;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class TestspringApplication {
public static void main(String[] args) {
SpringApplication.run(TestspringApplication.class, args);
}
}
@SpringBootApplication을 살펴보면,
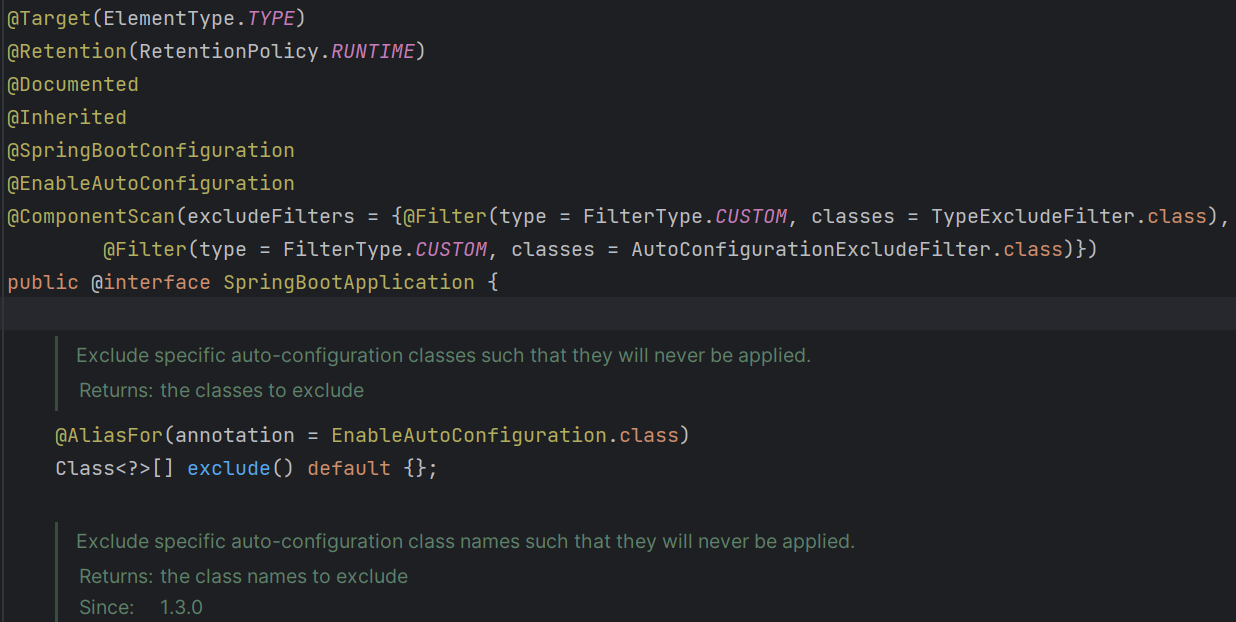
@SpringBootConfiguration, @EnableAutoConfiguration, @ComponentScan 이 있는데 각각에 대해서 간단하게 살펴보자.
1) @SpringBootConfiguration

인터페이스 설명을 보면, 구현 클래스가 @Configuration을 제공한다고 한다. 즉, @Configuration을 직접 정의하지 않아도 된다. @Configuration은 IoC 컨테이너에 Bean 들의 설정 정보를담기 위해서 사용한다.
2) @EnableAutoConfiguration

자동 구성은 개발자가 추가 하고 싶은 Bean 들을 추측하고 구성하는 것을 시도한다고 한다. 그 아래 설명을 보니까 라이브러리의 jar 파일도 자동으로 Bean으로 구성해주는 것 같다.
3) @ComponentScan

@Configuration에 Bean 들을 등록하고 의존성 주입하기 위해 사용하는 어노테이션이다. @Bean, @Component, @Configuration, @Service, @Controller 등 모두 이 컴포넌트 스캔의 대상이 된다.
2. 2
이제 애플리케이션을 실행했다고 치고, 사용자의 요청이 들어왔을 때 WAS 로서 SpringBoot가 어떻게 구동 되는지 알아보자
SpringBoot는 내장 Tomcat를 라이브러리로 가지고 있다. 따라서 앱 실행을 하면 Tomcat이 디폴트 포트인 8080에서 실행된다.

보통 웹 환경에서 서버에로의 사용자 요청 흐름은 축약해서 다음과 같다.
사용자 요청 -> 웹 서버 -> 웹 어플리케이션 서버(Tomcat)
Tomcat 내부에는 Servlet Container가 있는데, 이 서블릿 컨테이너는 서블릿들을 관리해주는 역할을 한다고 생각하면 된다.
-Servlet이란?
A servlet is a Java programming language class that is used to extend the capabilities of servers that host applications accessed by means of a request-response programming model.
(https://javaee.github.io/tutorial/servlets001.html#BNAFE)
라고 한다. 즉 요청-응답 구조를 이용하는 웹 애플리케이션 서버의 기능을 확장하는 기술? 직역하면 이 정도인데 애플리케이션 구동 중 요청-응답을 처리해주는 자바 객체 라고 생각해도 될 것 같다. init -> service -> destroy의 생명주기를 가진다.
-Servlet Container
서블릿 컨테이너는 이 서블릿, 즉 자바 객체들이 모여서 관리되는 공간이다. Servlet은 URL 매핑 하나 당 하나의 Servlet이 담당하게 된다. 매핑은 web.xml에서 수행하게 되는데, springboot를 사용하면 사실상 이 파일을 우리가 작성할 필요는 없다.

Servlet Container의 단점은, 동일한 uri에 대해 어떤 서비스 로직이 중복 되더라도 서로 다른 Servlet 객체들을 지정해줘야 한다는 비효율적인 측면이 있었다. 이를 DispatcherServlet을 사용하는 Spring 컨테이너와 결합하여 문제를 해결할 수 있다.
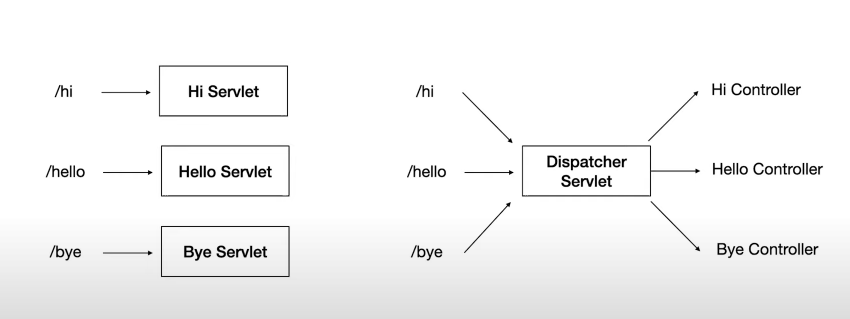
-Servlet을 이용한 Spring MVC 구조. --> WAS 안에는 Servlet Container와 Spring Container가 존재한다.

HTTP Request가 오면 먼저 Servlet Container가 반겨준다. 해당 요청을 스프링 컨테이너의 DispatcherServlet로 다시 보낸다. 그렇다면 요청을 받은 DispatcherServlet은 이후에 그 요청을 어떻게 처리할까? 그림으로 나타내면 아래와 같다.
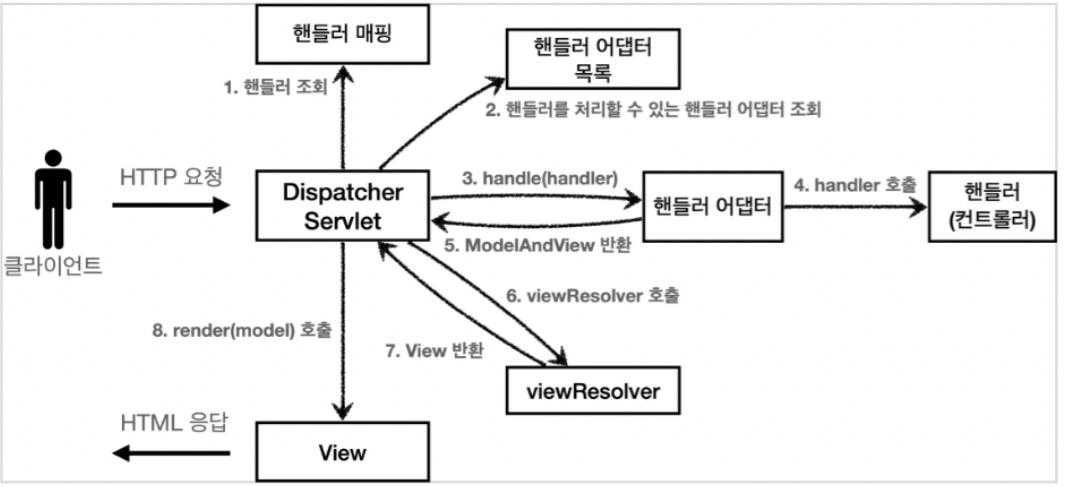
1) 먼저 HandlerMapping으로 보낸다. 우리가 흔히 사용하는 @RequestMapping과 @GetMapping("/uri") 등의 방식은 RequestMappingHandlerMapping 클래스다. (DefaultAnnotationHandlerMapping은 스프링3.2에서 deprecated). 여기서 해당하는 uri의 Controller를 찾은 후 HandlerAdapter로 보낸다.
2) HandlerAdapter를 통해 Controller의 메서드를 불러낼 수 있다.
3) 그 이후 우리에게 익숙한 어플리케이션 구조인 Controller - Service - Repository의 순서대로 로직 처리가 된다.
4) JSP나 타임리프 파일을 반환하고 싶다면 View Resolver와 View를 통해 data를 담아 클라이언트에게 반환되고, RestAPI 서버로 이용한다면 HttpMessageConverter를 거치게 된다.
기존 Servlet Container에서 Spring을 적용함으로써 개발자가 개발해야 되는 부분은 Controller를 통한 로직 처리로 축소했다.
(혹시 틀린 부분 있다면 알려주시면 감사하겠습니다..)
3. Enum 타입의 ordinal의 단점
세미나에서 스프링 엔티티의 Enum 타입 필드에 작성하는 어노테이션을 공부했다. 두 가지가 있는데, 하나는 @Enumerated(EnumType.ORDINAL)과 @Enumerated(EnumType.STRING)이다. 세미나에선 @Enumerated(EnumType.STRING)으로 Enum 타입에 대해 매핑했따. ORIDNAL은 쓰면 안될까?
이 파트에선 ORDINAL의 단점에 대해서 알아보고자 한다.
Enum을 Ordinal로 사용하게 되면 각각에 대해 int형 숫자가 붙게 된다. 예를 들어 아래와 같이 Enum 타입과 엔티티를 정의했다고 하면
public enum VipGrade {
BRONZE,
SILVER,
GOLD,
DIAMOND
}
@Entity
@Getter
@NoArgsConstructor
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Enumerated(EnumType.ORDINAL)
private VipGrade grade;
private int age;
}
이 상태에서 grade필드가 GOLD로 설정되어 있꼬 DB에 반영되면, grade 필드에는 정수값인 3이 들어가게 된다. 따로 지정하지 않는다면 enum 클래스에 지정된 순서대로 정해지기 때문이다.
여기까지는 별 문제가 없다. 근데 서비스 출시 1달 후에, 기획자가 갑자기 GOLD와 DIAMOND 사이에 PLATINUM 등급을 하나 더 만들자고 한다...
이때부터 문제가 발생한다. DB에 저장된 해당 필드 값을 전부 밀어서 변경해야 하기 때문이다. 심지어 BRONZE 아래 등급으로 IRON 하나 만들자고 하면????????
Ordinal의 이런 단점 때문에 String으로 많이 사용한다고 한다.
4. 스프링 빈의 생명 주기
스프링 빈의 생명 주기는 다음 단계와 같다.
1. 스프링 컨테이너 생성
Bean 들을 등록하기 위해 스프링 IoC 컨테이너가 생성 된다.
2. 스프링 빈 생성
스프링 빈에 해당하는 객체들이 생성된다.
3. 의존관계 주입
제어의 역전을 통해 스프링 컨테이너에서 관리되는 스프링 빈들 간의 의존관계를 주입해준다.
4. 초기화 콜백 메소드
스프링 빈의 라이프 사이클은 객체의 생성과 초기화를 다른 단계로 구분지어 진행한다.
초기화 콜백 메소드에는 여러 가지 방법이 있지만, 현재 @PostConstruct 어노테이션을 사용하는 방법이 가장 권장된다.
package com.example.testspring;
import jakarta.annotation.PostConstruct;
import org.springframework.stereotype.Component;
@Component
public class TestBean {
@PostConstruct
public void init() {
System.out.println("빈 콜맥 메서드 호출");
}
}이전 프로젝트에서 더미 데이터를 만들어야 할 때 사용했던 기억이 난다.
5. 소멸전 콜백 메소드
생성전과 마찬가지로 어노테이션을 이용한다. @PreDestroy를 사용한다.
package com.example.testspring;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
import org.springframework.stereotype.Component;
@Component
public class TestBean {
@PostConstruct
public void init() {
System.out.println("빈 생성전 콜백 메서드 호출");
}
@PreDestroy
public void destroy() {
System.out.println("빈 소멸전 콜백 메서드 호출");
}
}
4. 세미나에서 공부한 어노테이션 중 더 알고 싶은 어노테이션 3가지!
1) @RestController
코드 상으로 이 어노테이션을 타고 들어가면 이런 게 나온다.
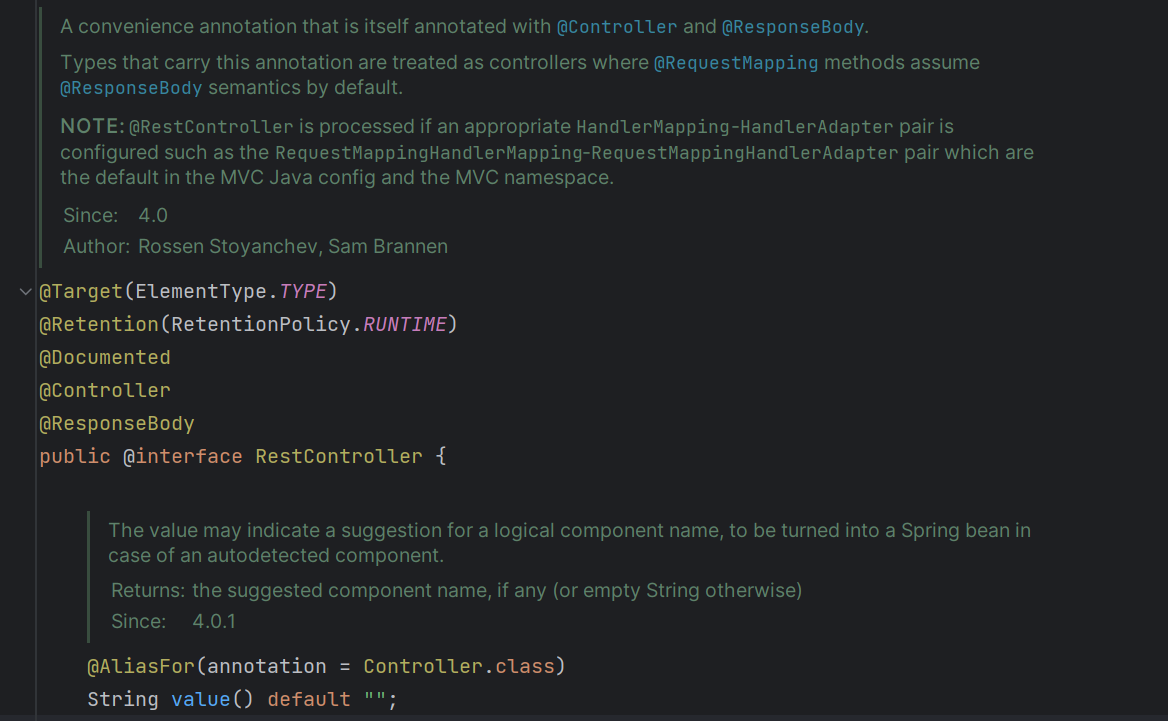
@Controller와 @ResponseBody를 포함하는 편리한 어노테이션이라고 설명하고 있다. 실제로 @ResponseBody와 @Controller가 있는 것을 확인할 수 있다.
그렇다면 @RestController를 사용하지 않고 @Controller와 @ResponseBody로 나눠서 사용하면 어떤 불편함이 있을지 코드로 알아보자.
일단 아래와 같은 코드로 API 테스트를 해봤다.
package com.example.testspring;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class TestController {
//@ResponseBody
@GetMapping("/api")
public UserDto hello() {
UserDto userDto = new UserDto("솝솝이", 25);
return userDto;
}
}package com.example.testspring;
public record UserDto(
String name,
int age
) {
}
Postman으로 테스트 해봤는데, 아래와 같은 오류가 떴다.

ViewResolver 다시 보란다. 지금 자바 객체를 리턴하고 있기 때문에, 오류가 발생하는 것은 당연하다. 이제 @ResponseBody의 주석을 지우고 다시 실행해 보면 잘되는 것을 알 수 있따.

여기서 @ResponseBody의 역할에 대해 알 수 있다. @ResponseBody 어노테이션을 사용하면, ViewResolver를 사용하지 않고 HttpMessageConverter를 호출한다. 이는 위에서 SpringBoot의 작동 방식에 대해서 언급한 것과 동일하다. 이때 인자가 객체이면 여러 구현체 중 MappingJackson2HttpMessageConverter 가 동작한다.


컨버터 내부에서 Jackson 라이브러리를 이용하여 객체를 Json으로 변환하거나, 혹은 반대 과정을 수행한다.
여기서 직렬화와 역직렬화의 개념이 나온다. 자바 객체와 Json간 직렬화, 역직렬화의 관계는
직렬화(serialization) - 자바 객체 -> Json
역직렬화 - Json -> 자바 객체 로 간단하게 나타낼 수 있다.
조금 길어진 것 같지만, 결국 @RestController는 이런 기능을 전부 포함하고 있다고 봐도 무방할 것 같다.
참고로 @RequestBody는 @ResponseBody와 거의 유사하게 정반대로 동작한다고 생각하면 될 것 같다.
2) @GeneratedValue
스프링 프로젝트 구성 시 Entity의 Id 필드 위에 붙여주는 어노테이션이다. API 문서를 보면,
Provides for the specification of generation strategies for the values of primary keys.
The GeneratedValue annotation may be applied to a primary key property or field of an entity or mapped superclass in conjunction with the Id annotation.
The use of the GeneratedValue annotation is only required to be supported for simple primary keys.
Use of the GeneratedValue annotation is not supported for derived primary keys.
라고 되어 있다.
- 이 어노테이션은 PK(Primary key) 값의 생성 전략을 구체화해준다.
- @Id와 함께 엔티티 필드나 매핑된 superclass의 pk 속성에 적용 된다.
- 이 어노테이션의 사용은 단순한 pk값을 지원하기 위해서만 필요하다
- 파생키에는 지원하지 않는다.
-GenerationType
아래 사진과 같이 키 생성 전략을 지정해줄 수 있다.
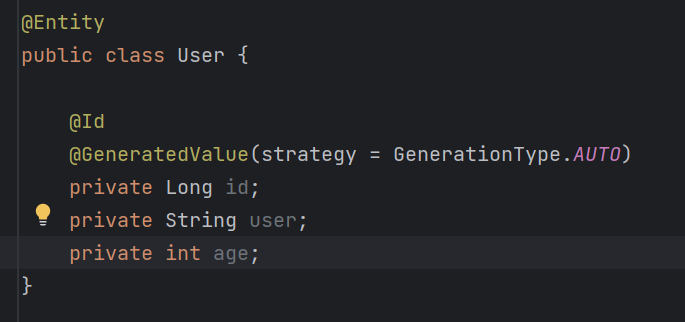
생성 전략에는 아래와 같이 몇 가지가 있다.
/*
* Copyright (c) 2008, 2022 Oracle and/or its affiliates. All rights reserved.
*
* This program and the accompanying materials are made available under the
* terms of the Eclipse Public License v. 2.0 which is available at
* http://www.eclipse.org/legal/epl-2.0,
* or the Eclipse Distribution License v. 1.0 which is available at
* http://www.eclipse.org/org/documents/edl-v10.php.
*
* SPDX-License-Identifier: EPL-2.0 OR BSD-3-Clause
*/
// Contributors:
// Linda DeMichiel - 2.1
// Linda DeMichiel - 2.0
package jakarta.persistence;
/**
* Defines the types of primary key generation strategies.
*
* @see GeneratedValue
*
* @since 1.0
*/
public enum GenerationType {
/**
* Indicates that the persistence provider must assign
* primary keys for the entity using an underlying
* database table to ensure uniqueness.
*/
TABLE,
/**
* Indicates that the persistence provider must assign
* primary keys for the entity using a database sequence.
*/
SEQUENCE,
/**
* Indicates that the persistence provider must assign
* primary keys for the entity using a database identity column.
*/
IDENTITY,
/**
* Indicates that the persistence provider must assign
* primary keys for the entity by generating an RFC 4122
* Universally Unique IDentifier.
*/
UUID,
/**
* Indicates that the persistence provider should pick an
* appropriate strategy for the particular database. The
* <code>AUTO</code> generation strategy may expect a database
* resource to exist, or it may attempt to create one. A vendor
* may provide documentation on how to create such resources
* in the event that it does not support schema generation
* or cannot create the schema resource at runtime.
*/
AUTO
}
-TABLE
주석 처리 된 내용을 보면 테이블을 이용하라고 나와있다. 키 생성 전용 테이블을 만들어서 데이터베이스의 시퀀스와 같은 기능을 구현하도록 하는 전략이다. 테이블 제네레이터를 반드시 이용해야 한다.
-SEQUENCE
DB의 Sequence Object를 사용해서 유일한 값을 순서대로 생성한다. 시퀀스 제네레이터가 필요하다.
-IDENTITY
키 생성을 데이터베이스에 위임한다. DB가 알아서 AUTO INCREMENT를 해준다. 영속성 컨텍스트에서 객체의 키 값에 대해 매핑을 해주기 위해서 , EntityManager를 통해 커밋 시점 이전인 영속화(persist) 이후 바로 insert 쿼리를 날려서 해당 데이터의 키 값을 받아와 세팅해준다. 이 방식의 단점은, JPA의 장점 중 하나인 쓰기 지연이 안된 다는 점이다. 즉, 모아서 한 꺼번에 쿼리 날리는게 안된다. 하나하나 insert 해줘야 한다.
-UUID
UUID를 이용해 키를 생성하는 전략이다.
-AUTO
특정 벤더에 따라 UUID를 제외한 위의 전략 중 하나를 전략으로 선택해준다. 고유성은 보장해주지만 특성 상 순서는 보장해주지 못함.
3) @SpringBootTest
/**
* Annotation that can be specified on a test class that runs Spring Boot based tests.
* Provides the following features over and above the regular <em>Spring TestContext
* Framework</em>:
* <ul>
* <li>Uses {@link SpringBootContextLoader} as the default {@link ContextLoader} when no
* specific {@link ContextConfiguration#loader() @ContextConfiguration(loader=...)} is
* defined.</li>
* <li>Automatically searches for a
* {@link SpringBootConfiguration @SpringBootConfiguration} when nested
* {@code @Configuration} is not used, and no explicit {@link #classes() classes} are
* specified.</li>
* <li>Allows custom {@link Environment} properties to be defined using the
* {@link #properties() properties attribute}.</li>
* <li>Allows application arguments to be defined using the {@link #args() args
* attribute}.</li>
* <li>Provides support for different {@link #webEnvironment() webEnvironment} modes,
* including the ability to start a fully running web server listening on a
* {@link WebEnvironment#DEFINED_PORT defined} or {@link WebEnvironment#RANDOM_PORT
* random} port.</li>
* <li>Registers a {@link org.springframework.boot.test.web.client.TestRestTemplate
* TestRestTemplate} and/or
* {@link org.springframework.test.web.reactive.server.WebTestClient WebTestClient} bean
* for use in web tests that are using a fully running web server.</li>
* </ul>
*
* @author Phillip Webb
* @author Andy Wilkinson
* @since 1.4.0
* @see ContextConfiguration
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@BootstrapWith(SpringBootTestContextBootstrapper.class)
@ExtendWith(SpringExtension.class)
public @interface SpringBootTest {
...
}
이 어노테이션은 스프링 부트에 기반한 통합테스트를 실행시키는 클래스에 붙여준다. 자동으로 @SpringBootConfiguration을 서치한다고 나와있는데, 이는 @SpringBootApplication에 포함되어있는 것이다. 즉 어플리케이션의 Config나 의존 관계를 그대로 가져와 테스트할 수 있다.
'솝 키워드 과제' 카테고리의 다른 글
| 4차 세미나 키워드 과제 (0) | 2024.05.08 |
|---|---|
| 3차 세미나 키워드 과제 (0) | 2024.04.26 |
| 1차 세미나 키워드 과제 (0) | 2024.03.31 |